
学习分享(第 2 期):从源码层面看 Redis 节省内存的设计
这里记录的是学习分享的内容,文章维护在 Github:studeyang/leanrning-share。
回顾
在文章《Redis 的 String 类型,原来这么占内存》中,我们学习了 SDS 的底层结构,发现 SDS 存储了很多的元数据,再加上全局哈希表的实现,使得 Redis String 类型在内存占用方面并不理想。
然后在文章《学习分享(第1期)之Redis:巧用Hash类型节省内存》中,我们学习了另一种节省内存的方案,使用 ziplist 结构的 Hash 类型,内存占用减少了一半,效果显著。
虽然我们在使用 String 类型后,占用了较多内存,但其实 Redis 是对 SDS 做了节省内存设计的。除此之外,Redis 在其他方面也都考虑了内存开销,今天我们就从源码层面来看看都做了哪些节省内存的设计。
文中代码版本为 6.2.4。
一、redisObject 的位域定义法
我们知道,redisObject 是底层数据结构如 SDS, ziplist 的封装,因此,redisObject 如果能做优化,最终也能带来节省内存的用户体验。在源码 server.h 中定义了 redisObject 的结构体,如下面代码所示:
1 |
|
type, encoding, lru, refcount 都是 redisObject 的元数据,redisObject 的结构如下图所示。
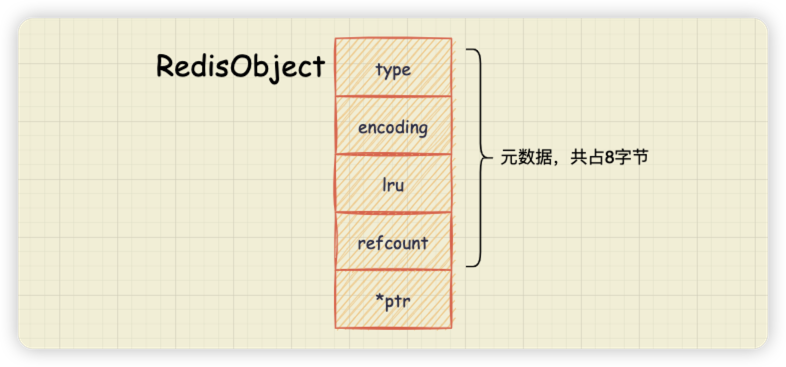
从代码中我们可以看到,在 type、encoding 和 lru 三个变量后面都有一个冒号,并紧跟着一个数值,表示该元数据占用的比特数。这种变量后使用冒号和数值的定义方法,实际上是 C 语言中的位域定义方法,可以用来有效地节省内存开销。
这种方法比较适用的场景是,当一个变量占用不了一个数据类型的所有 bits 时,就可以使用位域定义方法,把一个数据类型中的 bits(32 bits),划分成多个(3 个)位域,每个位域占一定的 bit 数。这样一来,一个数据类型的所有 bits 就可以定义多个变量了,从而也就有效节省了内存开销。
另外,SDS 的设计中,也有内存优化的设计,我们具体来看看有哪些。
二、SDS 的设计
在 Redis 3.2 版本之后,SDS 由一种数据结构变成了 5 种数据结构。分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,其中 sdshdr5 只被应用在了 Redis 中的 key 中,另外 4 种不同类型的结构头可以适配不同大小的字符串。
以 sdshdr8 为例,它的结构定义如下所示:
1 | struct __attribute__ ((__packed__)) sdshdr8 { |
不知道你有没有注意到,在 struct 和 sdshdr8 之间使用了 __attribute__ ((__packed__))。这是 SDS 的一个节省内存的设计–紧凑型字符串。
2.1 紧凑型字符串
什么是紧凑型字符串呢?
它的作用就是告诉编译器,在编译 sdshdr8 结构时,不要使用字节对齐的方式,而是采用紧凑的方式分配内存。默认情况下,编译器会按照 8 字节对齐的方式,给变量分配内存。也就是说,即使一个变量的大小不到 8 个字节,编译器也会给它分配 8 个字节。
举个例子。假设我定义了一个结构体 st1,它有两个成员变量,类型分别是 char 和 int,如下所示:
1 |
|
我们知道,char 类型占用 1 个字节,int 类型占用 4 个字节,但是如果你运行这段代码,就会发现打印出来的结果是 8。这就是因为在默认情况下,编译器会按照 8 字节对齐的方式,给 st1 结构体分配 8 个字节的空间,但是这样就有 3 个字节被浪费掉了。
那我用 __attribute__ ((__packed__)) 属性重新定义结构体 st2,同样包含 char 和 int 两个类型的成员变量,代码如下所示:
1 |
|
当你运行这段代码时,可以看到打印的结果是 5,这就是紧凑型内存分配,st2 结构体只占用 5 个字节的空间。
除此之外,Redis 还做了这样的优化:当保存的字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这种布局方式被称为 embstr 编码方式;当字符串大于 44 字节时,SDS 和 RedisObject 就分开布局了,这种布局方式被称为 raw 编码模式。
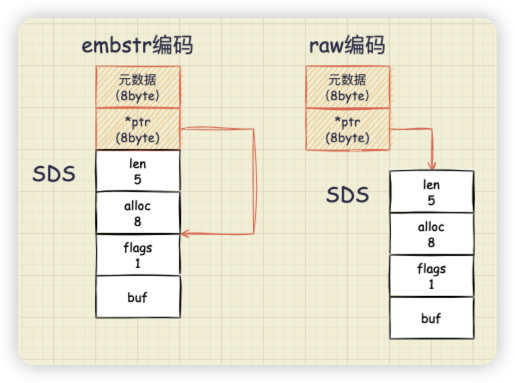
这部分的代码在 object.c 文件中:
1 |
|
当 len 的长度小于等于 OBJ_ENCODING_EMBSTR_SIZE_LIMIT (默认为 44 字节)时, createStringObject 函数就会调用 createEmbeddedStringObject 函数。这是 SDS 第二个节省内存的设计–嵌入式字符串。
在讲述嵌入式字符串之前,我们还是先来看看,当 len 的长度大于 OBJ_ENCODING_EMBSTR_SIZE_LIMIT (默认为 44 字节)时,这种普通字符串的创建过程。
2.2 RawString 普通字符串
对于 createRawStringObject 函数来说,它在创建 String 类型的值的时候,会调用 createObject 函数。createObject 函数主要是用来创建 Redis 的数据对象的。代码如下所示。
1 | robj *createRawStringObject(const char *ptr, size_t len) { |
createObject 函数有两个参数,一个是用来表示所要创建的数据对象类型,另一个是指向 SDS 对象的指针,这个指针是通过 sdsnewlen 函数创建的。
1 | robj *createObject(int type, void *ptr) { |
调用 sdsnewlen 函数创建完 SDS 对象的指针后,也分配了一块 SDS 的内存空间。接着,createObject 函数会给 redisObject 结构体分配内存空间,如上示代码【1】处。然后再把将传入的指针赋值给 redisObject 中的指针,如上示代码【2】处。
我们接着来看嵌入式字符串。
2.3 EmbeddedString 嵌入式字符串
通过上文我们知道,当保存的字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域。那么 createEmbeddedStringObject 函数是如何把 redisObject 和 SDS 的内存区域放置在一起的呢?
1 | robj *createEmbeddedStringObject(const char *ptr, size_t len) { |
首先,createEmbeddedStringObject 函数会分配一块连续的内存空间,这块内存空间的大小等于 redisObject 结构体的大小 + SDS 结构头 sdshdr8 的大小 + 字符串大小的总和, 并且再加上 1 字节结束字符“\0”。这部分代码如上【1】处。
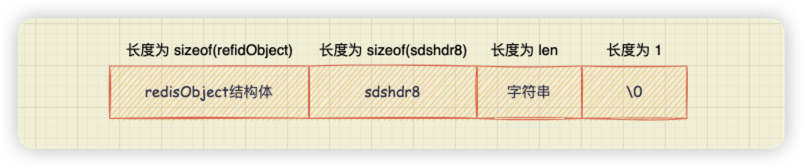
先分配了一块连续的内存空间,从而避免了内存碎片。
然后,createEmbeddedStringObject 函数会把参数中传入的指针 ptr 所指向的字符串,拷贝到 SDS 结构体中的字符数组,并在数组最后添加结束字符。这部分代码如上【2】处。
好了,以上就是 Redis 在设计 SDS 结构上节省内存的两个优化点,不过除了嵌入式字符串之外,Redis 还设计了压缩列表,这也是一种紧凑型的内存数据结构,下面我们再来学习下它的设计思路。
三、压缩列表的设计
为了方便理解压缩列表的设计与实现,我们先来看看它的创建函数 ziplistNew,这部分代码在 ziplist.c 文件中,如下所示:
1 | unsigned char *ziplistNew(void) { |
可以看到,ziplistNew 函数的逻辑很简单,就是创建一块连续的内存空间,大小为 ZIPLIST_HEADER_SIZE 和 ZIPLIST_END_SIZE 的总和,然后再把该连续空间的最后一个字节赋值为 ZIP_END,表示列表结束。
另外,在 ziplist.c 文件中也定义了 ZIPLIST_HEADER_SIZE、 ZIPLIST_END_SIZE 和 ZIP_END 的值,它们分别表示 ziplist 的列表头大小、列表尾大小和列表尾字节内容,如下所示。
1 | //ziplist的列表头大小 |
列表头包括 2 个 32 bits 整数和 1 个 16 bits 整数,分别表示压缩列表的总字节数 zlbytes,列表最后一个元素离列表头的偏移 zltail,以及列表中的元素个数 zllen;列表尾包括 1 个 8 bits 整数,表示列表结束。执行完 ziplistNew 函数创建一个 ziplist 后,内存布局就如下图所示。

注意,此时 ziplist 中还没有实际的数据,所以图中并没有画出来。
然后,当我们往 ziplist 中插入数据后,完整的内存布局如下图所示。
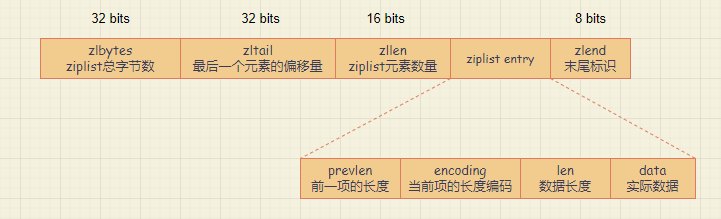
ziplist entry 包括三部分内容,分别是前一项的长度(prevlen)、当前项长度信息的编码结果(encoding),以及当前项的实际数据(data)。
当我们往 ziplist 中插入数据时,ziplist 会根据数据是字符串还是整数,以及它们的大小进行不同的编码,这种根据数据大小进行相应编码的设计思想,正是 Redis 为了节省内存而采用的。
1 | unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) { |
此处源码在下文中还会提及,为了讲述方便,这里标识为【源码A处】。
此外,每个列表项 entry 中都会记录前一项的长度,因为每个列表项的长度不一样, Redis 会根据数据长度选择不同大小的字节来记录 prevlen。
3.1 使用不同大小的字节来记录 prevlen
举个例子,假设我们统一使用 4 字节记录 prevlen,如果前一个列表项只是一个 5 字节的字符串“redis”,那我们用 1 个字节(8 bits)就能表示 0~256 字节长度的字符串了。此时,prevlen 用 4 字节记录,就有 3 字节浪费掉了。
下面我们就来看看 Redis 是如何根据数据长度选择不同大小的字节来记录 prevlen 的。
通过上面的 __ziplistInsert 函数即【源码A处】可以看到,ziplist 在对 prevlen 编码时,会先调用 zipStorePrevEntryLength 函数,该函数代码如下所示:
1 | unsigned int zipStorePrevEntryLength(unsigned char *p, unsigned int len) { |
可以看到,zipStorePrevEntryLength 函数会判断前一个列表项是否小于 ZIP_BIG_PREVLEN(ZIP_BIG_PREVLEN 的值是 254)。如果是的话,那么 prevlen 就使用 1 字节表示;否则,zipStorePrevEntryLength 函数就调用 zipStorePrevEntryLengthLarge 函数进一步编码。
zipStorePrevEntryLengthLarge 函数会先将 prevlen 的第 1 字节设置为 254,然后使用内存拷贝函数 memcpy,将前一个列表项的长度值拷贝至 prevlen 的第 2 至第 5 字节。最后,zipStorePrevEntryLengthLarge 函数返回 prevlen 的大小,为 5 字节。
1 | int zipStorePrevEntryLengthLarge(unsigned char *p, unsigned int len) { |
好了,在了解了 prevlen 使用 1 字节和 5 字节两种编码方式后,我们再来学习下 encoding 的编码方法。
3.2 使用不同大小的字节来记录 encoding 编码
我们回到上面的 __ziplistInsert 函数即【源码A处】,可以看到执行完 zipStorePrevEntryLength 函数逻辑后,紧接着会调用 zipStoreEntryEncoding 函数。
ziplist 在 zipStoreEntryEncoding 函数中,针对整数和字符串,就分别使用了不同字节长度的编码结果。
1 | unsigned int zipStoreEntryEncoding(unsigned char *p, unsigned char encoding, unsigned int rawlen) { |
可以看到当数据是不同长度字符串或是整数时,编码结果的长度 len 大小不同。
总之,针对不同长度的数据,使用不同字节大小的元数据信息 prevlen 和 encoding 来记录, 这种方法可以有效地节省内存开销。

参考资料
- 极客时间《Redis源码剖析与实战》
- redis 源码 v6.2.4:https://github.com/redis/redis/tree/6.2.4
相关文章
也许你对下面文章也感兴趣。
学习分享(第 2 期):从源码层面看 Redis 节省内存的设计

