一、题目描述
题目链接:https://leetcode.cn/problems/ti-huan-kong-ge-lcof/
难易程度:简单
将一个字符串中的空格替换成 “%20”。
1 | Input: |

题目链接:https://leetcode.cn/problems/ti-huan-kong-ge-lcof/
难易程度:简单
将一个字符串中的空格替换成 “%20”。
1 | Input: |

题目链接:https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/
难易程度:中等
在一个 n * m 的二维数组中,每一行都按照从左到右递增排序,每一列也按照从上到下递增排序。给定一个数,判断这个数是否在该二维数组中。
1 | Consider the following matrix: |

题目链接:https://leetcode.cn/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/
难易程度:简单
找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
1 | 输入: |

在我们的生产环境中有一张表:courier_consume_fail_message,是存放消息消费失败的数据的,设计之初,这张表的数据量评估在万级别以下,因此没有建立索引。
但目前发现,该表的数据量已经达到百万级别,原因产生了大量的重试消费,这导致了该表的慢查询。
因此需要清理该表数据。而实际上,使用 DELETE 命令删除数据后,我们发现查询速度并没有显著提高,甚至可能会降低。为什么?
因为 DELETE 命令只是标记该行数据为“已删除”状态,并不会立即释放该行数据在磁盘中所占用的存储空间,这样就会导致数据文件中存在大量的碎片,从而影响查询性能。所以,除了删除表记录外,还需要清理磁盘碎片。
在表碎片清理前,我们关注以下四个指标。
SHOW TABLE STATUS LIKE 'courier_consume_fail_message';SELECT count(*) FROM courier_consume_fail_message;SELECT count(*) FROM courier_consume_fail_message where created_at < '2023-04-19 00:00:00';EXPLAIN SELECT * FROM courier_consume_fail_message WHERE service='courier-transfer-mq';1 | -- 清理磁盘碎片 |
以下是清理前后的指标对比。

本文来自我最近正在学习的课程,极客时间胡峰的专栏文章《程序员进阶攻略》。文中观点颇为认同,分享给你,部分内容我作了精简,内容如下。
几年前,我给团队负责的整个系统写过一些公共库,有一次同事发现这个库里存在一个 Bug,并告诉了我出错的现象。然后我便去修复这个 Bug,最终只修改了一行代码,但发现一上午就这么过去了。
一上午只修复了一个 Bug,而且只改了一行代码,到底发生了什么?时间都去哪里了?以前觉得自己写代码很快,怎么后来越来越慢了?我认真地思考了这个问题,开始认识到我的编程方式和习惯在那几年已经慢慢发生了变化,形成了明显的两个阶段的转变。这两个阶段是:

最近由于一行单元测试代码没有写 Assert 断言,导致了项目在 CI 过程中没有通过,于是遭到了某位同事的吐槽,在修改我的代码后写上了一句提交信息。

我想,做为技术人,修改这条 Commit 信息还是不难的,于是我通过本文介绍的技巧完成了修改,效果如下:

其实修改历史提交信息很简单。
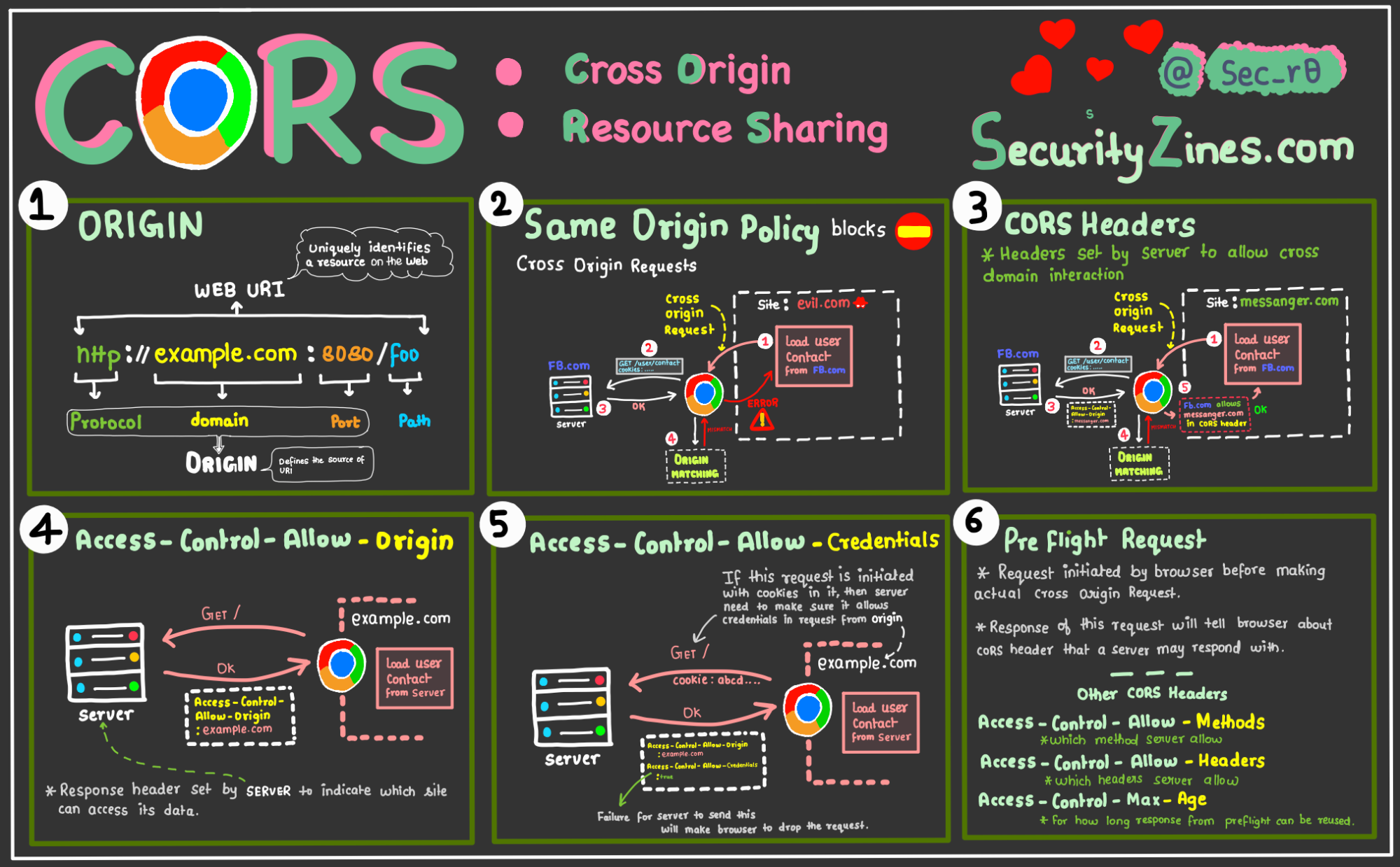
熟悉 HTTP 协议的同学都知道,ORS 是 HTTP 协议中的一种安全策略,全称是 Cross-origin resource sharing,中文名称是跨域资源共享,是一种让受限资源能够被其他域名的页面访问的一种机制。
下图描述了 CORS 机制。

本文来自我最近正在学习的课程,极客时间郭东白的专栏文章。这篇文章让我在架构悟道上有所觉悟,分享给你,希望对你有所启发,部分内容我作了精简,内容如下。
人类的各种活动都要遵循事物的客观生命周期。不论是农业社会种田打渔,还是资本社会投资创业,行动太早或太晚,都会颗粒无收。技术也一样,也有自己的生命周期。而我们作为架构师,如果看不清技术的生命周期,那么所设计的架构就没法儿向更有生命力的新技术借力,自己的职业生涯也会受限。
在架构设计的过程中,架构师会有一个相对确定的商业和技术选择空间。在这个选择的空间内,架构师做技术选型的时候,必须要考虑到所依赖的商业和技术模块的生命周期。这个时候,我们就需要看准技术趋势,选择已经有规模优势或者是即将有规模优势的技术,而不是选择接近衰老期的技术。
但是啊,有的人能够看准一个技术的生命周期, 而有些人却做不到。为什么?

06期:使用 OPTIMIZER_TRACE 窥探 MySQL 索引选择的秘密
这里记录的是学习分享内容,文章维护在 Github:studeyang/leanrning-share。
优化查询语句的性能是 MySQL 数据库管理中的一个重要方面。在优化查询性能时,选择正确的索引对于减少查询的响应时间和提高系统性能至关重要。但是,如何确定 MySQL 的索引选择策略?MySQL 的优化器是如何选择索引的?
在这篇《索引失效了?看看这几个常见的情况!》文章中,我们介绍了索引区分度不高可能会导致索引失效,而这里的“不高”并没有具体量化,实际上 MySQL 会对执行计划进行成本估算,选择成本最低的方案来执行。具体我们还是通过一个案例来说明。
还是以人物表为例,我们来看一下优化器是怎么选择索引的。
建表语句如下:
1 | CREATE TABLE `person` ( |
然后插入 10 万条数据:
1 | create PROCEDURE `insert_person`() |