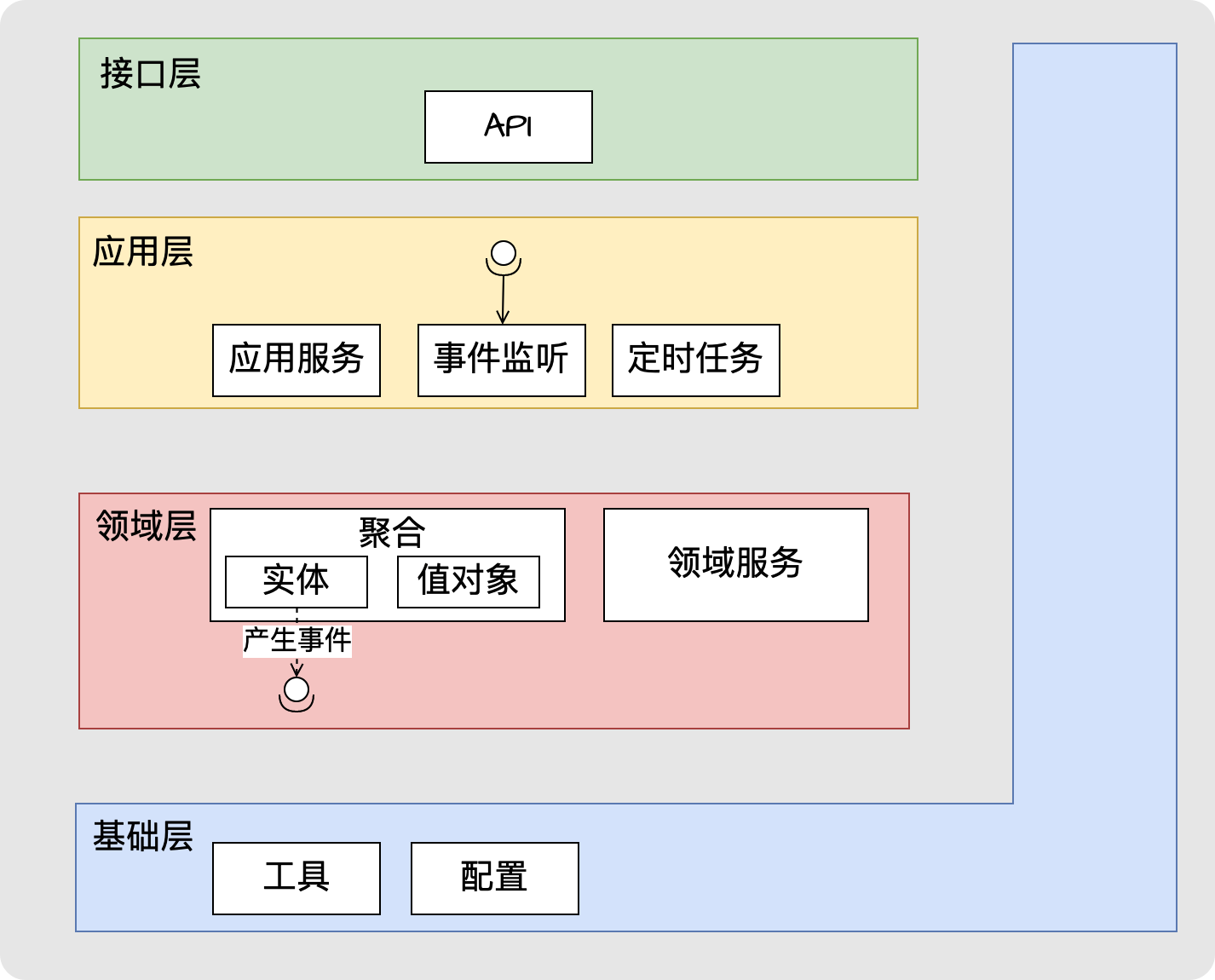
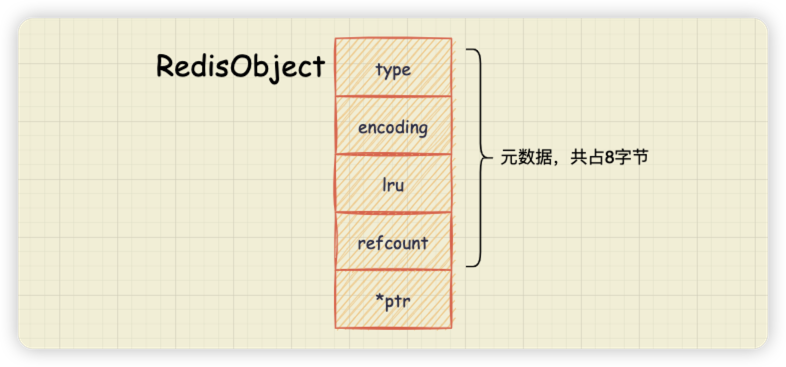
本文摘要:浅谈应用架构、业务架构、技术架构。
什么是架构?
说到架构,这个概念没有很清晰的范围划分,也没有一个标准的定义,每个人的理解可能都不一样。
架构在百度百科中是这样定义的:架构,又名软件架构,是有关软件整体结构与组件的抽象描述,用于指导大型软件系统各个方面的设计。
我们可以理解为:架构设计的主要目的是为了解决软件系统复杂度带来的问题。
卡内基·梅隆大学的玛丽·肖(Mary Shaw)和戴维·加兰(David Garlan)在文章《软件架构介绍》(An Introduction to Software Architecture)中写到:
“When systems are constructed from many components, the organization of the overall system-the software architecture-presents a new set of design problems.”
译:随着软件系统规模的增加,计算相关的算法和数据结构不再构成主要的设计问题;当系统由许多部分组成时,整个系统的组织,也就是所说的“软件架构”,导致了一系列新的设计问题。
软件架构的核心价值,即是控制系统的复杂性,将核心业务逻辑和技术细节的分离与解耦。
架构师的职责是努力训练自己的思维,用它去理解复杂的系统,通过合理的分解和抽象,理解并解析需求,创建有用的模型,确认、细化并扩展模型,管理架构;能够进行系统分解形成整体架构,能够正确的技术选型,能够制定技术规格说明并有效推动实施落地。